on type safety in LangChain TS
The unpredictable and non-deterministic nature of the LLM output makes ensuring type safety challenging

At Octomind, we are using Large Language Models (LLMs) to interact with web app UIs and extract test case steps that we want to generate. We use the LangChain library to build interaction chains with LLMs. The LLM receives a task prompt, and we as developers provide tools the model can utilize to solve the task.
The unpredictable and non-deterministic nature of the LLM output makes ensuring type safety quite a challenge. LangChain's approach to parsing input and handling errors often leads to unexpected and inconsistent outcomes within the type system. I'd like to share what I learned about parsing and error handling of LangChain.
I will explain:
- Why did we go for TypeScript in the first place?
- The issue with LLM output
- How a type error can go unnoticed
- What consequences this can have
*** all code examples are using LangChain TS on the main branch on September 22nd, 2023 (roughly version 0.0.153).
Why LangChain TS instead of Python?
There are two languages supported by LangChain - Python and JS/TypeScript.
There were some pros and some cons with TypeScript:
- On the con side - we have to live with the fact that the TypeScript implementation is somewhat lagging behind the Python version - in code and even more so in documentation. This is a solvable issue, if you are willing to trade the documentation for just going through the source code.
- On the pro side - we don't have to write another service in a different language since we are using TypeScript elsewhere, and we allegedly get guaranteed type safety, of which we are big fans here.
We decided to go for the TypeScript version of LangChain to implement parts of our AI-based test discoveries.
Full disclosure, I didn't look into how the Python version handles the issues described below. Have you found similar issues in the python version? Feel free to share them directly in the GitHub issue I created, find the link at the end of the article.
The issue with types in LLMs
In LangChain, you can provide a set of tools that may be called by the model if it deems it necessary. For our purposes, a tool is simply a class with a _call function that does something that the model can not do on its own, like click on a button on a web page. The arguments to that function are provided by the model.
When your tool implementation depends on the developer knowing the input format (in contrast to just doing something with text generated by the model), LangChain provides a class called StructuredTool.
The StructuredTool adds a zod schema to the tool, which is used to parse whatever the model decides to call the tool with, so that we can use this knowledge in our code.
Let's build our "click" example under the assumption that we want the model to give us a query selector to click on:
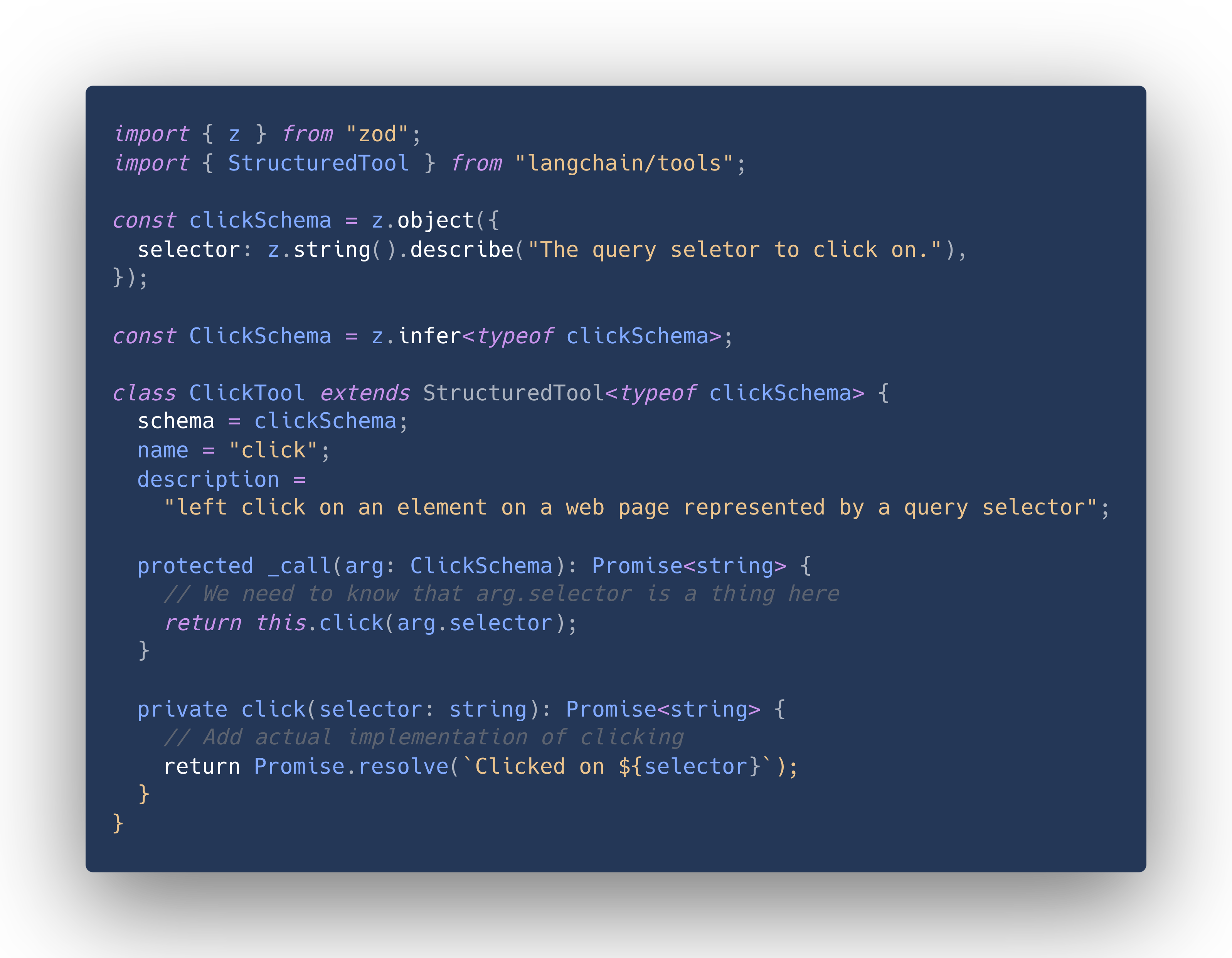
Now when you look at this class, it seems reasonably simple without a lot of potential for things to go wrong. But how does the model actually know what schema to supply? It has no intrinsic functionality for this, it just generates a string response to a prompt.
When LangChain informs the model about the tools at its disposal, it will generate format instructions for each tool. These instructions define what JSON is, and what the specific input schema the model should generate to use a tool.
For this, LangChain will generate an addition to your own prompt that looks something like this:
You have access to the following tools.
You must format your inputs to these tools to match their "JSON schema" definitions below.
"JSON Schema" is a declarative language that allows you to annotate and validate JSON documents.
For example, the example "JSON Schema" instance {"properties": {"foo": {"description": "a list of test words", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}}
would match an object with one required property, "foo". The "type" property specifies "foo" must be an "array", and the "description" property semantically describes it as "a list of test words". The items within "foo" must be strings.
Thus, the object {"foo": ["bar", "baz"]} is a well-formatted instance of this example "JSON Schema". The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here are the JSON Schema instances for the tools you have access to:
click: left click on an element on a web page represented by a query selector, args: {"selector":{"type":"string","description":"The query selector to click on."}}
Don't trust the LLM
Now we have a best-effort way to make the model call our tool with inputs in the correct schema. Best effort unfortunately does not guarantee anything. It is entirely possible, that the model generates input that does not adhere to the schema.
So let's take a look at the implementation of StructuredTool to see how it deals with that issue. StructuredTool.call is the function that eventually calls our _call method from above.
It starts like this:
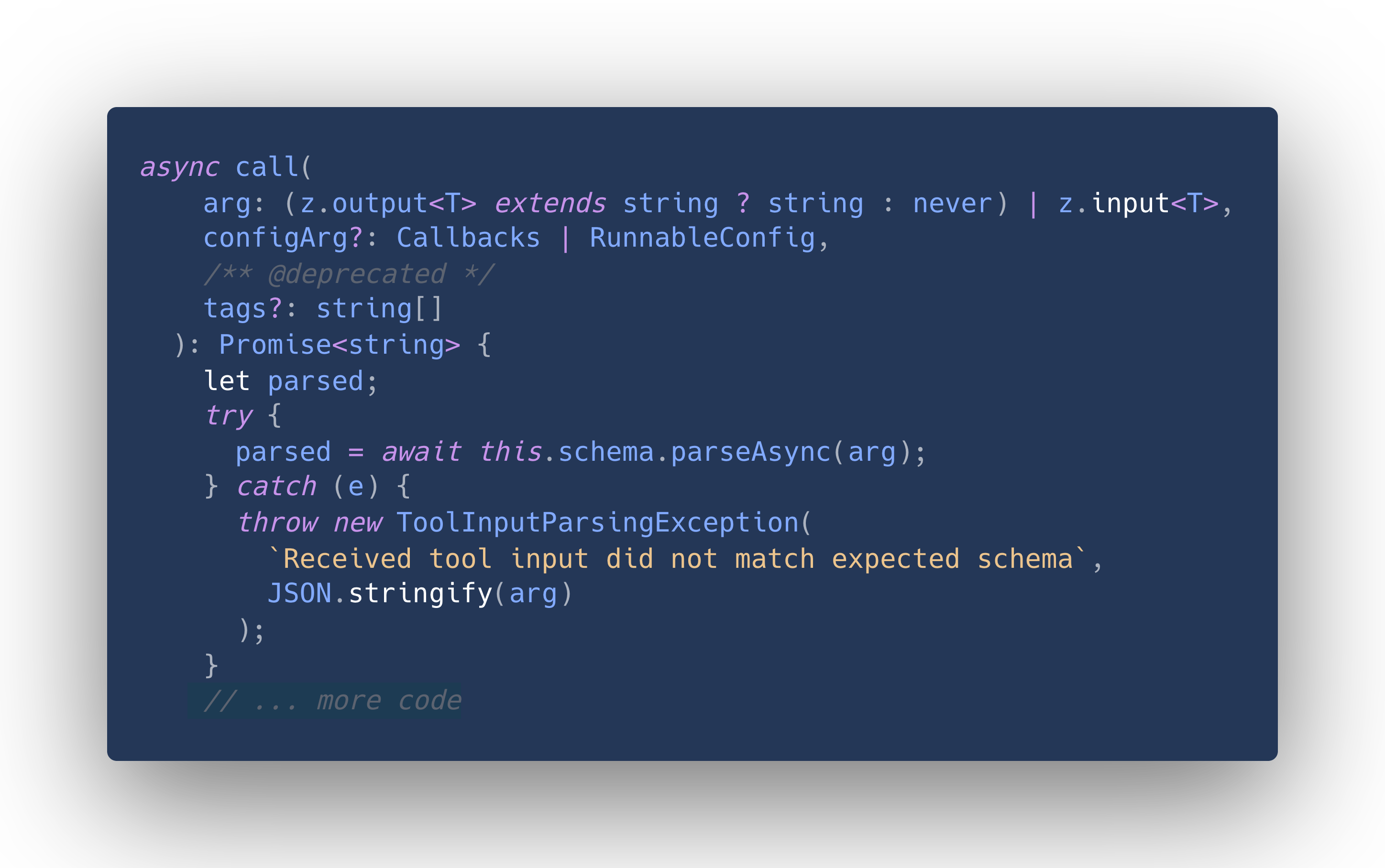
The signature of arg is interpreted as follows:
If after parsing the tool's schema, the output can be just a string, this can also be a string, or whatever object the schema defines as input. This is the case if you define your schema as schema = z.string().
In our case, our schema can not be parsed to a string, so this simplifies to the type { selector: string }, or ClickSchema.
But is this actually the case?
According to the implementation, we only check that the input actually adheres to the schema inside of call. The signature reads like we have already made some assumptions about the input.
So one might replace the signature with something like:

But looking at it further, even this has issues. The only thing we know for certain is that the model will give us a string. This means there are two options:
1. call really should have the following signature:
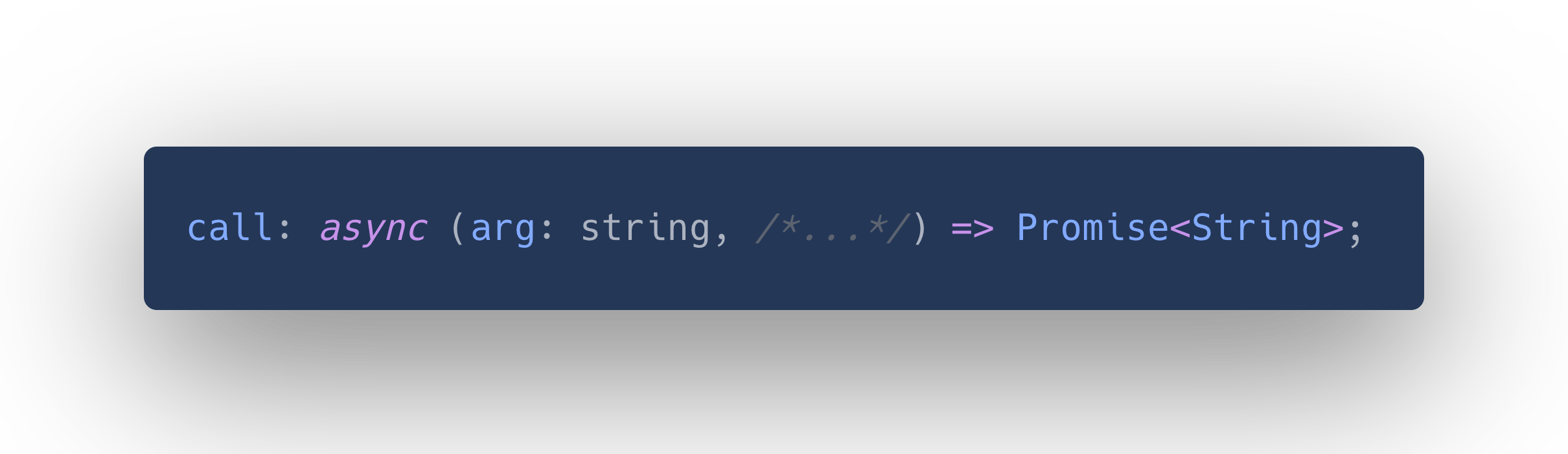
2. There is another element to this
- Something must have already decided that the string returned by the model is valid JSON and have parsed it.
- In case that z.output<T> extends string, something somewhere must have already decided that string is an acceptable input format for the tool, and we do not need to parse JSON. (A string by itself is not valid JSON, JSON.parse("foo") will result in a SyntaxError).
Introducing the OutputParser class
Of course, the second option is what is happening. For this use case, LangChain provides a concept called OutputParser.
Let's take a look at the default one (StructuredChatOuputParser) and its parse method in particular.
We don't need to understand every detail, but we can see that this is where the string that the model produces is parsed to JSON, and errors are thrown if it is not valid JSON.
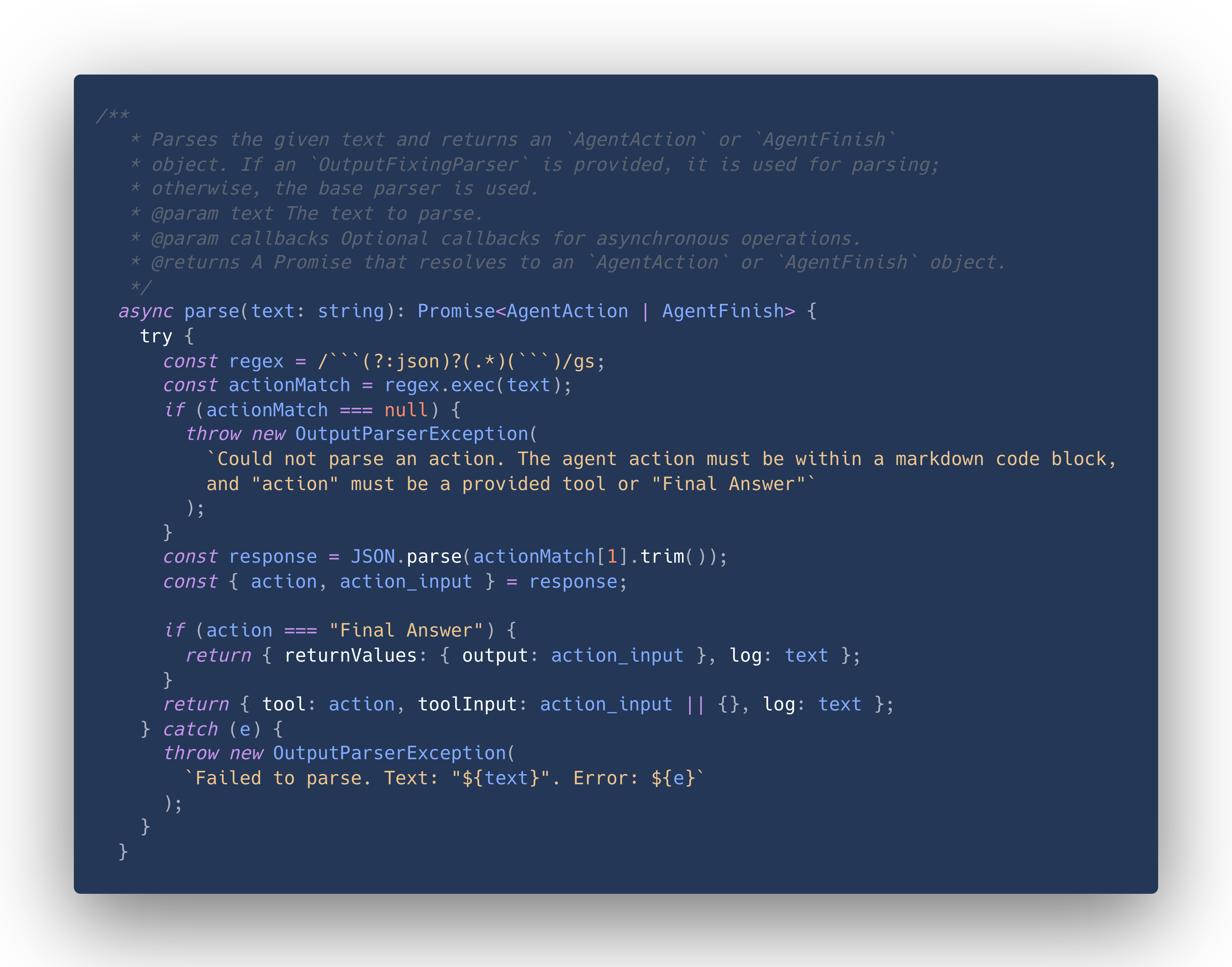
So, from this we either get AgentAction or AgentFinish. We don't need to concern ourselves with AgentFinish, since it is just a special case to indicate that the interaction with the model is done.
AgentAction is defined as:
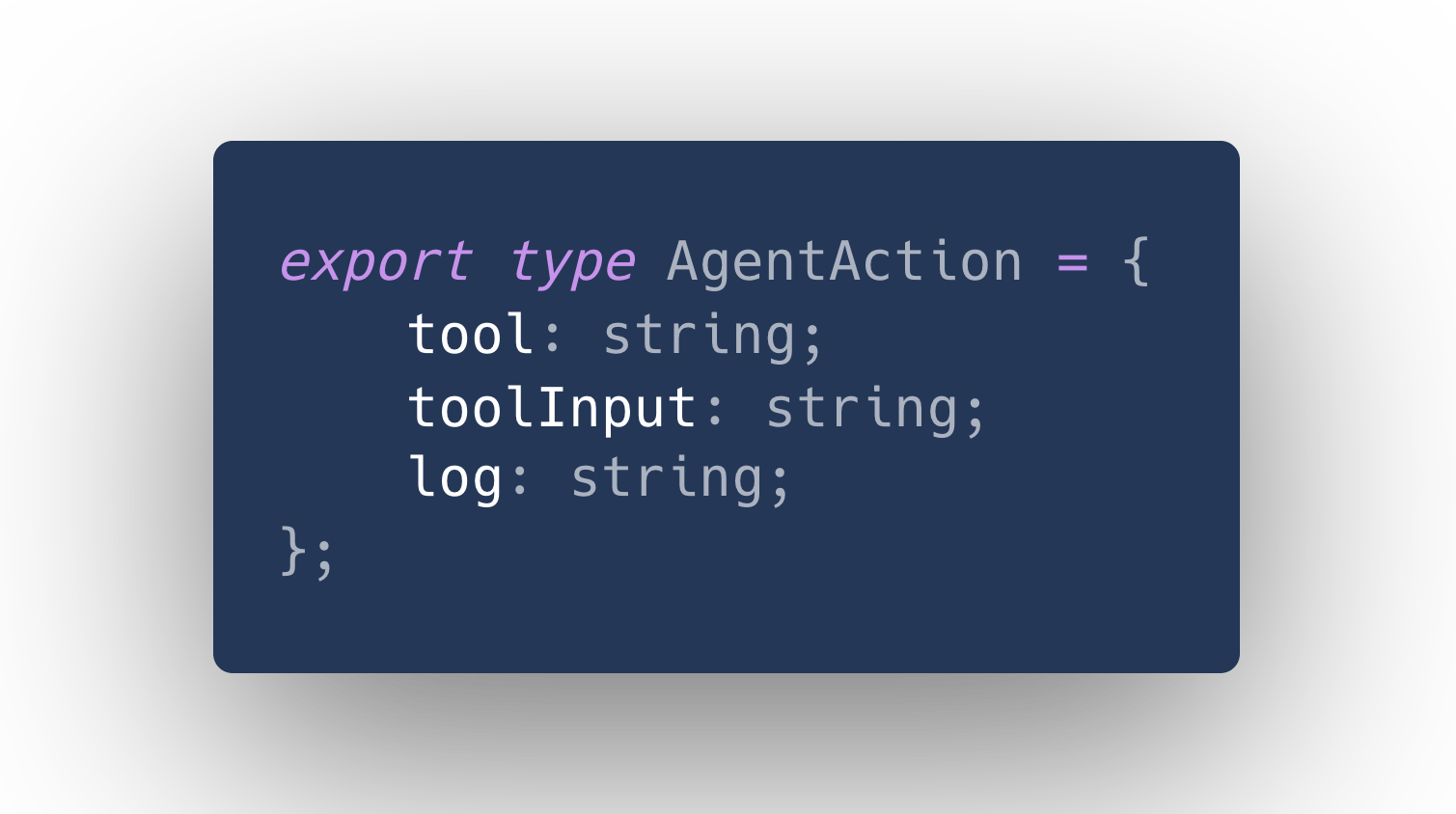
By now you might have already seen - neither AgentAction nor the StructuredChatOutputParserWithRetries is generic, and there is no way to connect the type of toolInput with our ClickSchema.
Since we don't know which tool the agent has actually selected, we can not (easily) use generics to represent the actual type, so this is expected. But worse, toolInput is typed as string, even though we just used JSON.parse to get it!
Consider the positive case where the model produced output that matches our schema, let's say the string "{"selector": "myCoolButton"}" (wrapped in all the extra fluff LangChain requires to correctly parse). Using JSON.parse, this will deserialize to an object { selector: "myCoolButton" } and not a string.
But because JSON.parse's return type is any, the typescript compiler has no chance of realizing this. Unfortunately for us, this also means that we, as developers, have a hard time to realize this.
The impact on our production code
To understand why this is troublesome, we need to look into the execution loop where the AgentActions are used to actually invoke the tool.
This happens here in AgentExecutor._call. We don't really need to understand everything that this class does. Think of it as the wrapper that handles the interaction of the model with the tool implementations to actually call them.
The _call method is quite long, so here is a reduced version that only contains parts relevant for our problem (these methods are simplified parts of _call and not in the actual code base of LangChain).
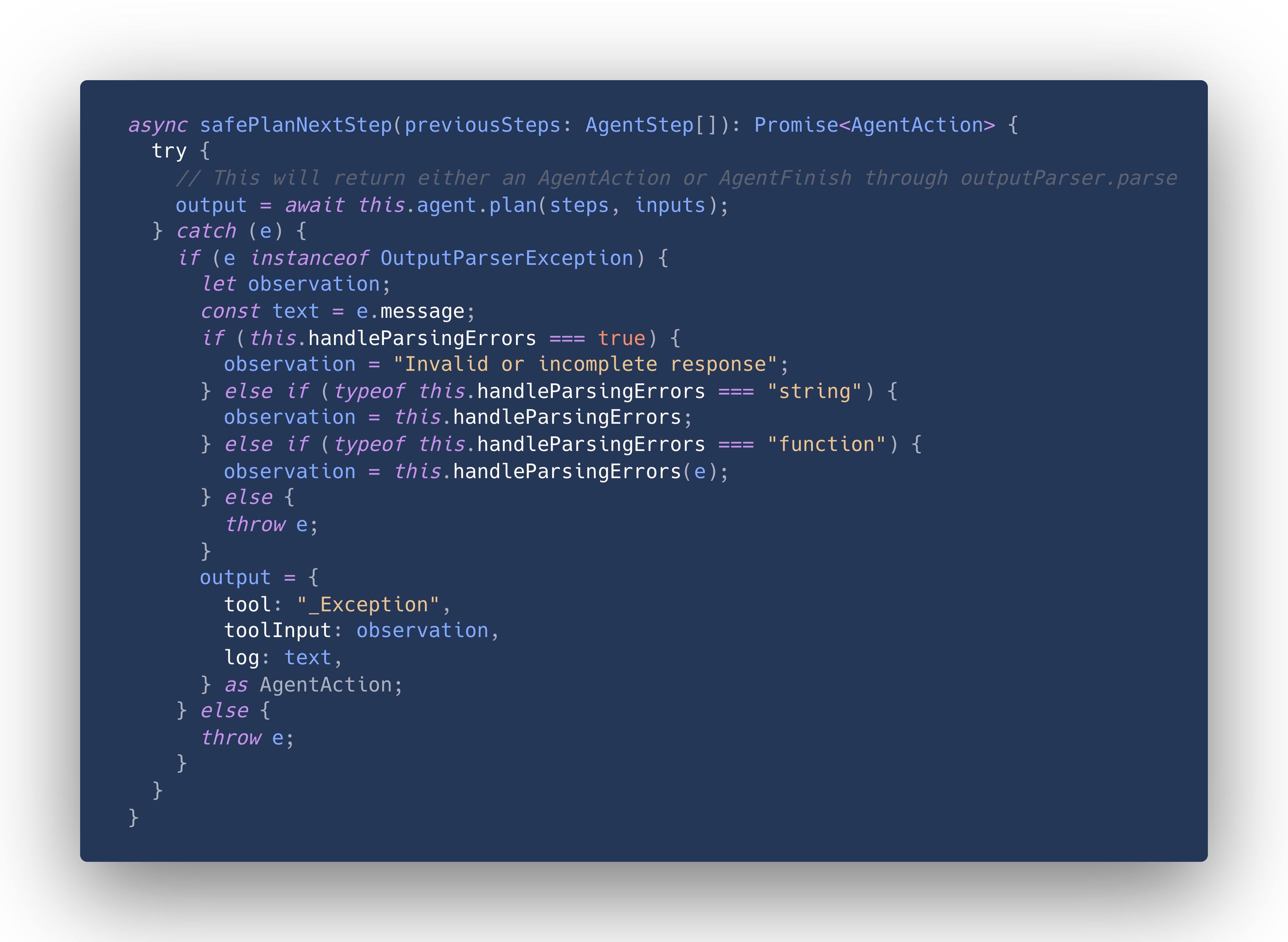
The first thing that happens in the loop is to look for the next action to execute. This is where the parsing using the OutputParser comes in, and where its exceptions are handled.
You can see that in the case of an error, the toolInput field will always be a string (if this.handleParsingErrors is a function, the return type is also string).
But we have just seen above, that in the non-error case toolInput will be parsed JSON! This is inconsistent behavior, we never parse the output of handleParsingErrors to JSON.
Let's look at how the loop continues. The next step is to call the selected tool with the given input:

We only pass the previously computed output on to the tool in tool.call(action.toolInput)!
And in case this causes another error, we re-use the same function to handle parsing errors that will return a string that is supposed to be the tool output in the error case.
Let's summarize all the issues:
- We parse the model's output to JSON and use that parsed result to call a tool
- If the parsing succeeds, we call the tool with any valid JSON
- If the parsing fails, we call the tool with a string
- The tool parses the input with zod, which will only work in the error case if the schema is just a const stringSchema = z.string()
- We have not covered this, but using const stringSchema = z.string() as the tool schema will not type check at all, since the generic argument of StructuredTool is T extends z.ZodObject<any, any, any, any>, and typeof stringSchema does not fulfil that constraint
- The signature of tool.call allows this to type check, since we don't know specifically which tool we have at the moment, so string and any json is potentially valid
- The actual type check for this happens at runtime inside this function
- The developer implementing the tool has no idea about this. Since only StructuredTool._call is abstract, you will always get what the schema indicates, but StructuredTool.call will fail, even if you have supplied a function handleParsingErrors.
- Whatever the tool gets called with is serialized into AgentAction.toolInput: string, which is not correctly typed
- The library user has access to the AgentSteps with wrongly typed AgentActions, since it is possible to request them as a return value of the overall loop using returnIntermediateSteps=true.
Whatever the developer does now is definitely not type safe!
How did we run into this problem?
At Octomind, we are using the AgentSteps to extract the test case steps that we want to generate. We noticed that the model often makes the same errors with the tool input format.
Recall our ClickSchema, which is just { selector: string }.
In our clicking example it would either generate according to the schema, or { element: string }, or just a string which is the value we want, like "myCoolButton".
So we built an auto-fixer for these common error cases. The fixer basically just checks whether it can fix the input using either of the options above. The earliest we can inject this code without overwriting a lot of the planning logic that LangChain provides is in StructuredTool.call.
We can not handle it using handleParsingErrors, since that receives only the error as input, and not the original input. Once you are overwriting StructuredTool.call, you are relying on the signature of that function to be correct, which we just saw is not the case.
At this point, I was stuck having to figure out all of the above to see why I am getting wrongly typed inputs.
The solution to type safety
While these hurdles can be frustrating, they also present opportunities to take a deep dive into the library and come up with possible solutions instead of complaining.
I have opened two issues at LangChain JS/TS to discuss ideas on how to solve these problems:
- Issue 1 - https://github.com/langchain-ai/langchainjs/issues/2710
- Issue 2 - https://github.com/langchain-ai/langchainjs/issues/2711
Feel free to jump in!

Veith Röthlingshöfer
ML engineer at Octomind